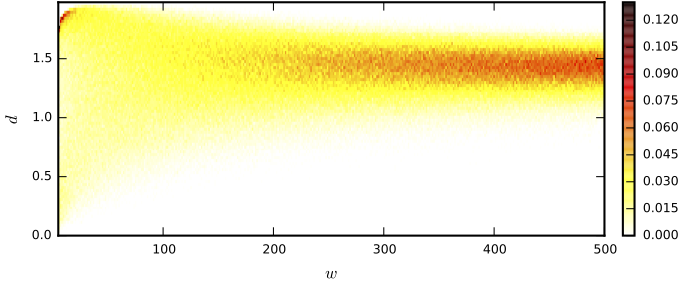
 The detection of very similar patterns in a time series, commonly called motifs, has received continuous and increasing attention from diverse scientific communities. In particular, recent approaches for discovering similar motifs of different lengths have been proposed. In this work, we show that such variable-length similarity-based motifs cannot be directly compared, and hence ranked, by their normalized dissimilarities. Specifically, we find that length-normalized motif dissimilarities still have intrinsic dependencies on the motif length, and that lowest dissimilarities are particularly affected by this dependency. Moreover, we find that such dependencies are generally non-linear and change with the considered data set and dissimilarity measure. Based on these findings, we propose a solution to rank (previously obtained) motifs of different lengths and measure their significance. This solution relies on a compact but accurate model of the dissimilarity space, using a beta distribution with three parameters that depend on the motif length in a non-linear way. We believe the incomparability of variable-length dissimilarities could have an impact beyond the field of time series, and that similar modeling strategies as the one used here could be of help in a more broad context and in diverse application scenarios.
J. Serrà, I. Serra, A. Corral, & J.L. Arcos. Ranking and significance of variable-length similarity-based time series motifs. Expert Systems with Applications. In Press. [arXiv] [DOI]
0 Comments
Your comment will be posted after it is approved.
Leave a Reply. |
Archives
September 2016
|
 RSS Feed
RSS Feed
