FEATURED PUBLICATIONS
Here you will find a selection of five of my relatively recent publications.
To get the full list (since 2007) you can click here or browse my Google Scholar profile.
Blow: a single-scale hyperconditioned flow for non-parallel raw-audio voice conversion.
|
J. Serrà, S. Pascual, & C. Segura.
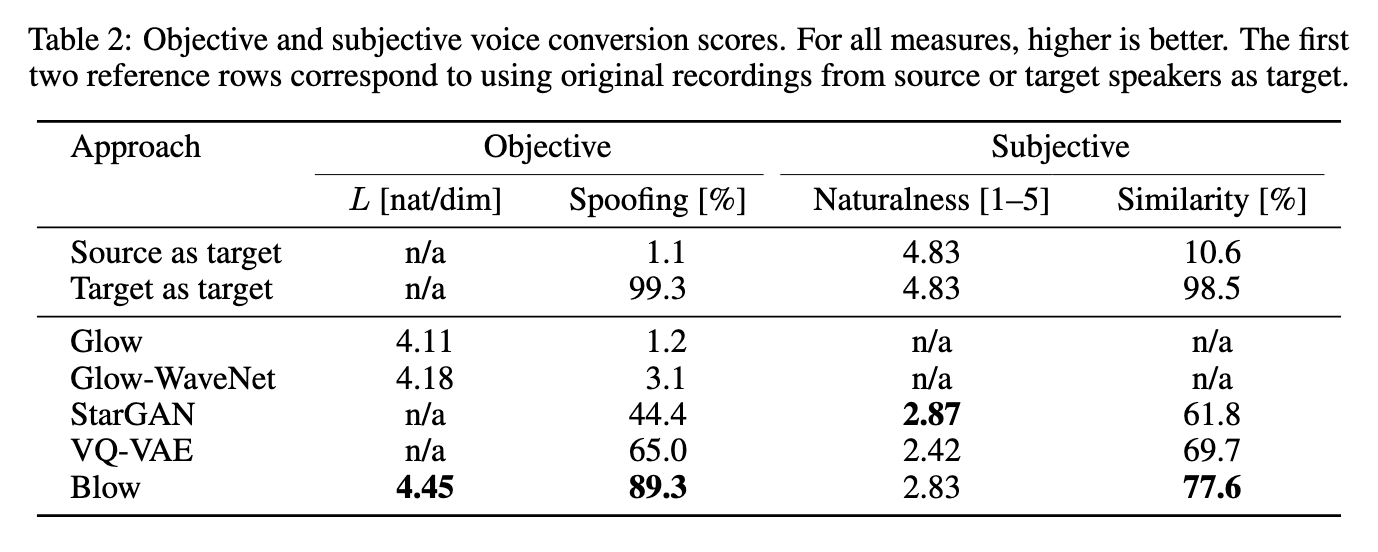
ArXiv: 1906.00794. Jun 2019. End-to-end models for raw audio generation are a challenge, specially if they have to work with non-parallel data, which is a desirable setup in many situations. Voice conversion, in which a model has to impersonate a speaker in a recording, is one of those situations. In this paper, we propose Blow, a single-scale normalizing flow using hypernetwork conditioning to perform many-to-many voice conversion between raw audio. Blow is trained end-to-end, with non-parallel data, on a frame-by-frame basis using a single speaker identifier. We show that Blow compares favorably to existing flow-based architectures and other competitive baselines, obtaining equal or better performance in both objective and subjective evaluations. We further assess the impact of its main components with an ablation study, and quantify a number of properties such as the necessary amount of training data or the preference for source or target speakers. Links: [arXiv] [Code] [Examples] |
|
Learning problem-agnostic speech representations from multiple self-supervised tasks.
|
S. Pascual, M. Ravanelli, J. Serrà, A. Bonafonte, & Y. Bengio.
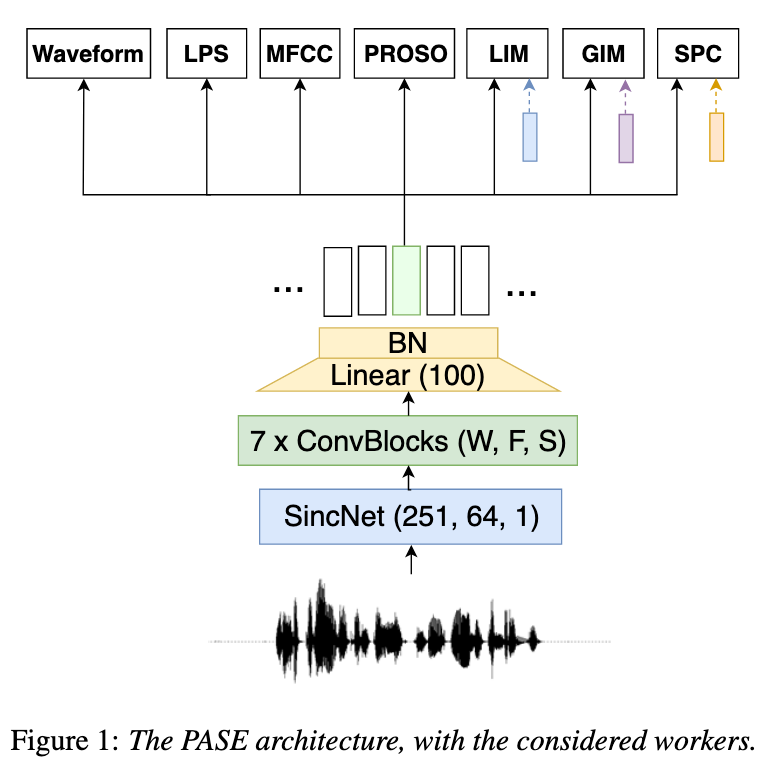
Proc. of the Conf. of the Int. Speech Communication Assoc. (INTERSPEECH). Sep 2019. Learning good representations without supervision is still an open issue in machine learning, and is particularly challenging for speech signals, which are often characterized by long sequences with a complex hierarchical structure. Some recent works, however, have shown that it is possible to derive useful speech representations by employing a self-supervised encoder-discriminator approach. This paper proposes an improved self-supervised method, where a single neural encoder is followed by multiple workers that jointly solve different self-supervised tasks. The needed consensus across different tasks naturally imposes meaningful constraints to the encoder, contributing to discover general representations and to minimize the risk of learning superficial ones. Experiments show that the proposed approach can learn transferable, robust, and problem-agnostic features that carry on relevant information from the speech signal, such as speaker identity, phonemes, and even higher-level features such as emotional cues. In addition, a number of design choices make the encoder easily exportable, facilitating its direct usage or adaptation to different problems. Links: [arXiv] [Code+model] |
|
Overcoming catastrophic forgetting with hard attention to the task.
|
J. Serrà, D. Surís, M. Miron, & A. Karatzoglou.
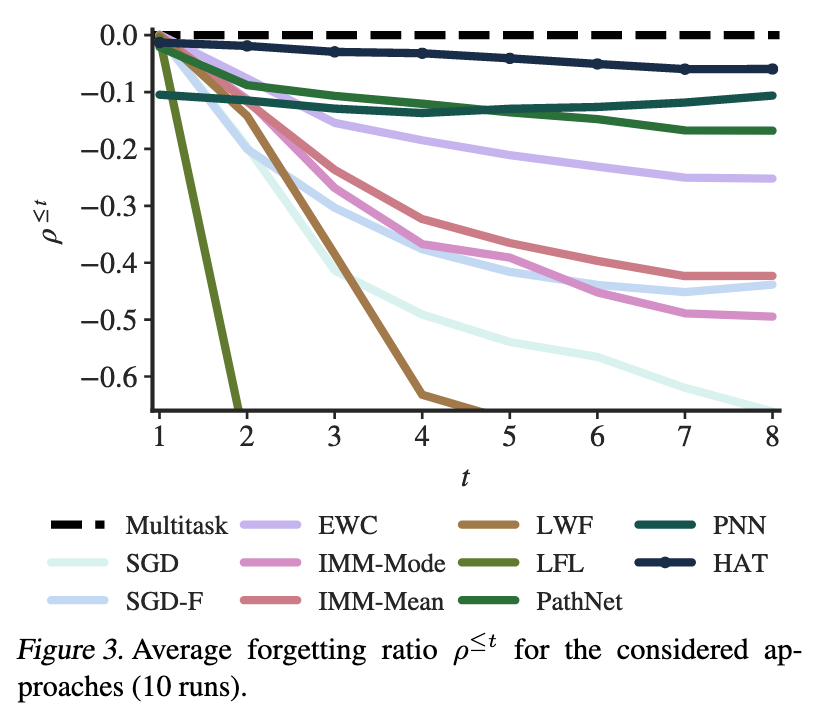
Proc. of the Int. Conf. on Machine Learning (ICML) 80: 4555-4564. Jul 2018. Catastrophic forgetting occurs when a neural network loses the information learned in a previous task after training on subsequent tasks. This problem remains a hurdle for artificial intelligence systems with sequential learning capabilities. In this paper, we propose a task-based hard attention mechanism that preserves previous tasks' information without affecting the current task's learning. A hard attention mask is learned concurrently to every task, through stochastic gradient descent, and previous masks are exploited to condition such learning. We show that the proposed mechanism is effective for reducing catastrophic forgetting, cutting current rates by 45 to 80%. We also show that it is robust to different hyperparameter choices, and that it offers a number of monitoring capabilities. The approach features the possibility to control both the stability and compactness of the learned knowledge, which we believe makes it also attractive for online learning or network compression applications. Links: [arXiv] [PMLR] [Code] |
|
Getting deep recommenders fit: Bloom embeddings for sparse binary input/output networks.
|
J. Serrà & A. Karatzoglou.
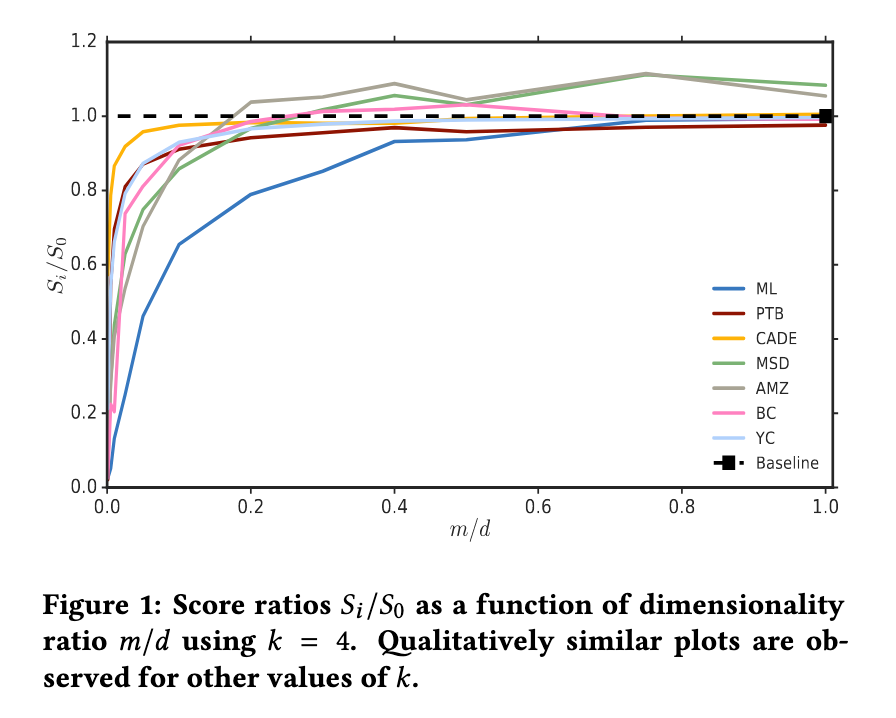
Proc. of the ACM Conf. on Recommender Systems (RecSys), pp. 279-287. Aug 2017. Recommendation algorithms that incorporate techniques from deep learning are becoming increasingly popular. Due to the structure of the data coming from recommendation domains (i.e., one-hot-encoded vectors of item preferences), these algorithms tend to have large input and output dimensionalities that dominate their overall size. This makes them difficult to train, due to the limited memory of graphical processing units, and difficult to deploy on mobile devices with limited hardware. To address these difficulties, we propose Bloom embeddings, a compression technique that can be applied to the input and output of neural network models dealing with sparse high-dimensional binary-coded instances. Bloom embeddings are computationally efficient, and do not seriously compromise the accuracy of the model up to 1/5 compression ratios. In some cases, they even improve over the original accuracy, with relative increases up to 12%. We evaluate Bloom embeddings on 7 data sets and compare it against 4 alternative methods, obtaining favorable results. We also discuss a number of further advantages of Bloom embeddings, such as 'on-the-fly' constant-time operation, zero or marginal space requirements, training time speedups, or the fact that they do not require any change to the core model architecture or training configuration. Links: [arXiv] [DOI] |
|
Particle swarm optimization for time series motif discovery.
|
J. Serrà & J.L. Arcos.
Knowledge-Based Systems 92: 127-137. Jan 2016. Efficiently finding similar segments or motifs in time series data is a fundamental task that, due to the ubiquity of these data, is present in a wide range of domains and situations. Because of this, countless solutions have been devised but, to date, none of them seems to be fully satisfactory and flexible. In this article, we propose an innovative standpoint and present a solution coming from it: an anytime multimodal optimization algorithm for time series motif discovery based on particle swarms. By considering data from a variety of domains, we show that this solution is extremely competitive when compared to the state-of-the-art, obtaining comparable motifs in considerably less time using minimal memory. In addition, we show that it is robust to different implementation choices and see that it offers an unprecedented degree of flexibility with regard to the task. All these qualities make the presented solution stand out as one of the most prominent candidates for motif discovery in long time series streams. Besides, we believe the proposed standpoint can be exploited in further time series analysis and mining tasks, widening the scope of research and potentially yielding novel effective solutions. Links: [arXiv] [DOI] [Code] |
|
