Tonal representations for music retrieval: from version identification to query-by-humming5/12/2012
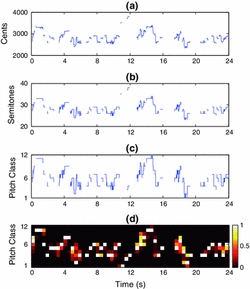 In this study we compare the use of different music representations for retrieving alternative performances of the same musical piece, a task commonly referred to as version identification. Given the audio signal of a song, we compute descriptors representing its melody, bass line and harmonic progression using state-of-the-art algorithms. These descriptors are then employed to retrieve different versions of the same musical piece using a dynamic programming algorithm based on nonlinear time series analysis. First, we evaluate the accuracy obtained using individual descriptors, and then we examine whether performance can be improved by combining these music representations (i.e. descriptor fusion). Our results show that whilst harmony is the most reliable music representation for version identification, the melody and bass line representations also carry useful information for this task. Furthermore, we show that by combining these tonal representations we can increase version detection accuracy. Finally, we demonstrate how the proposed version identification method can be adapted for the task of query-by-humming. We propose a melody-based retrieval approach, and demonstrate how melody representations extracted from recordings of a cappella singing can be successfully used to retrieve the original song from a collection of polyphonic audio. The current limitations of the proposed approach are discussed in the context of version identification and query-by-humming, and possible solutions and future research directions are proposed.
J. Salamon, J. Serrà, and E. Gómez. Tonal representations for music retrieval: from version identification to query-by-humming. Int. Journal of Multimedia Information Retrieval, special issue on Hybrid Music Information Retrieval. In press.  Next week I'll be attending the ISMIR conference in Porto, Portugal, where I coauthor 4 papers:
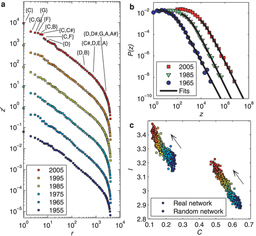 Popular music is a key cultural expression that has captured listeners' attention for ages. Many of the structural regularities underlying musical discourse are yet to be discovered and, accordingly, their historical evolution remains formally unknown. Here we unveil a number of patterns and metrics characterizing the generic usage of primary musical facets such as pitch, timbre, and loudness in contemporary western popular music. Many of these patterns and metrics have been consistently stable for a period of more than fifty years. However, we prove important changes or trends related to the restriction of pitch transitions, the homogenization of the timbral palette, and the growing loudness levels. This suggests that our perception of the new would be rooted on these changing characteristics. Hence, an old tune could perfectly sound novel and fashionable, provided that it consisted of common harmonic progressions, changed the instrumentation, and increased the average loudness.
J. Serrà, Á. Corral, M. Boguñá, M. Haro, and J. Ll. Arcos. Measuring the evolution of contemporary western popular music. Scientific Reports 2: 521. Jul 2012. Digital sampling can be defined as the use of a fragment of another artist’s recording in a new work, and is common practice in popular music production since the 1980’s. Knowledge on the origins of samples hold valuable musicological information, which could in turn be used to organise music collections. Yet the automatic recognition of samples has not been addressed in the music retrieval community. In this paper, we introduce the problem, situate it in the field of content-based music retrieval and present a first strategy to approach it. Evaluation confirms that our modified optimised fingerprinting approach is indeed a viable strategy.
J. Van Balen, M. Haro, and J. Serrà. Automatic identification of samples in hip hop music. Proc. of the Int. Symp. on Computer Music Modeling and Retrieval (CMMR), pp. 544-551. London, UK. June 2012. In this contribution, we discuss content-based retrieval strategies that follow the query-by-example paradigm: given an audio query, the task is to retrieve all documents that are somehow similar or related to the query from a music collection. Such strategies can be loosely classified according to their specificity, which refers to the degree of similarity between the query and the database documents. Here, high specificity refers to a strict notion of similarity, whereas low specificity to a rather vague one. Furthermore, we introduce a second classification principle based on granularity, where one distinguishes between fragment-level and document-level retrieval. Using a classification scheme based on specificity and granularity, we identify various classes of retrieval scenarios, which comprise audio identification, audio matching, and version identification. For these three important classes, we give an overview of representative state-of-the-art approaches, which also illustrate the sometimes subtle but crucial differences between the retrieval scenarios. Finally, we give an outlook on a user-oriented retrieval system, which combines the various retrievalstrategies in a unified framework.
P. Grosche, M. Müller, and J. Serrà. Audio content-based music retrieval. In Multimodal Music Processing, M. Müller, M. Goto, and M. Schedl eds., Dagstuhl Follow-Ups, Dagstuhl Publishing, Wadern, Germany, vol. 3, ch. 9, pp. 157-174. Apr 2012. |
Archives
September 2016
|
 RSS Feed
RSS Feed
