|
I'll be giving a talk at DataBeersBCN next Tuesday. The title is "Quick-and-dirty facts about deep learning", and in it I'll expose a series of facts and myths about these models.
0 Comments
 Raga is the melodic framework of Indian art music. It is a core concept used in composition, performance, organization, and pedagogy. Automatic rāga recognition is thus a fundamental information retrieval task in Indian art music. In this paper, we propose the time-delayed melody surface (TDMS), a novel feature based on delay coordinates that captures the melodic outline of a raga. A TDMS describes both the tonal and the temporal characteristics of a melody, using only an estimation of the predominant pitch. Considering a simple k-nearest neighbor classifier, TDMSs outperform the state-of-the-art for raga recognition by a large margin. We obtain 98% accuracy on a Hindustani music dataset of 300 recordings and 30 ragas, and 87% accuracy on a Carnatic music dataset of 480 recordings and 40 ragas. TDMSs are simple to implement, fast to compute, and have a musically meaningful interpretation. Since the concepts and formulation behind the TDMS are generic and widely applicable, we envision its usage in other music traditions beyond Indian art music.
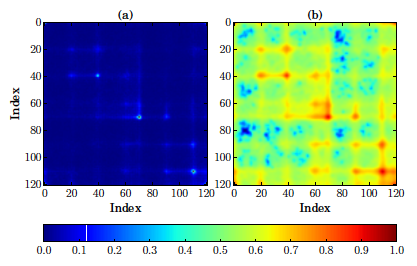
S. Gulati, J. Serrà, K.K. Ganguli, S. Senturk, & X. Serra. Time-delayed melody surfaces for raga recognition. Proc. of the Int. Soc. for Music Information Retrieval Conf. (ISMIR), pp. 751-757. Aug 2016. [MTG] [ISMIR] 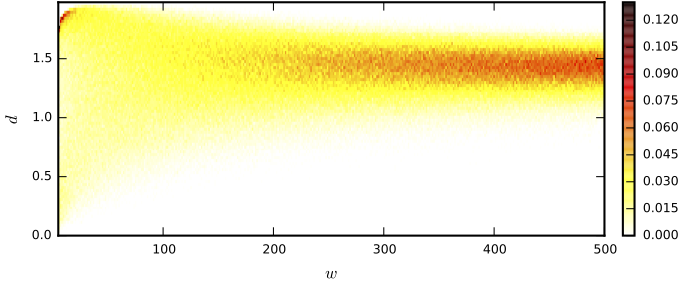 The detection of very similar patterns in a time series, commonly called motifs, has received continuous and increasing attention from diverse scientific communities. In particular, recent approaches for discovering similar motifs of different lengths have been proposed. In this work, we show that such variable-length similarity-based motifs cannot be directly compared, and hence ranked, by their normalized dissimilarities. Specifically, we find that length-normalized motif dissimilarities still have intrinsic dependencies on the motif length, and that lowest dissimilarities are particularly affected by this dependency. Moreover, we find that such dependencies are generally non-linear and change with the considered data set and dissimilarity measure. Based on these findings, we propose a solution to rank (previously obtained) motifs of different lengths and measure their significance. This solution relies on a compact but accurate model of the dissimilarity space, using a beta distribution with three parameters that depend on the motif length in a non-linear way. We believe the incomparability of variable-length dissimilarities could have an impact beyond the field of time series, and that similar modeling strategies as the one used here could be of help in a more broad context and in diverse application scenarios.
J. Serrà, I. Serra, A. Corral, & J.L. Arcos. Ranking and significance of variable-length similarity-based time series motifs. Expert Systems with Applications. In Press. [arXiv] [DOI] 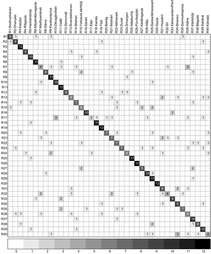 Automatic rāga recognition is one of the fundamental computational tasks in Indian art music. Motivated by the way seasoned listeners identify rāgas, we propose a rāga recognition approach based on melodic phrases. Firstly, we extract melodic patterns from a collection of audio recordings in an unsupervised way. Next, we group similar patterns by exploiting complex networks concepts and techniques. Drawing an analogy to topic modeling in text classification, we then represent audio recordings using a vector space model. Finally, we employ a number of classification strategies to build a predictive model for rāga recognition. To evaluate our approach, we compile a music collection of over 124 hours, comprising 480 recordings and 40 rāgas. We obtain 70% accuracy with the full 40-rāga collection, and up to 92% accuracy with its 10-rāga subset. We show that phrase-based rāga recognition is a successful strategy, on par with the state of the art, and sometimes outperforms it. A by-product of our approach, which arguably is as important as the task of rāga recognition, is the identification of rāga-phrases. These phrases can be used as a dictionary of semantically-meaningful melodic units for several computational tasks in Indian art music.
To appear in ICASSP 2016: S. Gulati, J. Serrà, V. Ishwar, S. Senturk, & X. Serra. Phrase-based raga recognition using vector space modeling. Proc. of the IEEE Int. Conf. on Acoustics, Speech, and Signal Processing (ICASSP). In Press. [MTG] 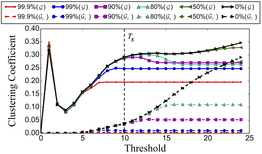 Rāga motifs are the main building blocks of the melodic structures in Indian art music. Therefore, the discovery and characterization of such motifs is fundamental for the computational analysis of this music. We propose an approach for discovering rāga motifs from audio music collections. First, we extract melodic patterns from a collection of 44 hours of audio comprising 160 recordings belonging to 10 rāgas. Next, we characterize these patterns by performing a network analysis, detecting non-overlapping communities, and exploiting the topological properties of the network to determine a similarity threshold. With that, we select a number of motif candidates that are representative of a rāga, the rāga motifs. For a formal evaluation we perform listening tests with 10 professional musicians. The results indicate that, on an average, the selected melodic phrases correspond to rāga motifs with 85% positive ratings. This opens up the possibilities for many musically-meaningful computational tasks in Indian art music, including human-interpretable rāga recognition, semantic-based music discovery, or pedagogical tools.
To appear in ICASSP 2016: S. Gulati, J. Serrà, V. Ishwar, & X. Serra. Discovering raga motifs by characterizing communities in networks of melodic patterns. Proc. of the IEEE Int. Conf. on Acoustics, Speech, and Signal Processing (ICASSP). In Press. [MTG] |
Archives
September 2016
|
 RSS Feed
RSS Feed
